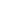摘要
本篇博客介绍了AlphaPose,这是一种基于自顶向下范式的多人姿态估计框架,针对传统方法在检测框定位偏差、热图量化误差及冗余姿态抑制等核心问题,提出多阶段优化方案:首先设计对称空间变换网络(SSTN),通过仿射变换动态校正检测框偏移,解决因定位不准导致的关键点中心化误差;其次,提出对称积分关键点回归(SIKR),引入幅值对称梯度(ASG)优化热图到坐标的转换过程,显著降低手部、足部等精细部位的量化误差;此外提出参数化姿态非极大抑制(P-NMS),基于关键点距离和姿态方向差异动态判定冗余检测,有效消除密集人群中的误检;最后通过姿态引导区域生成器(PGPG)模拟检测器误差分布,生成多样化训练数据提升模型鲁棒性。该框架在精度与实时性上表现突出,但高度依赖检测器性能且计算复杂度较高。
Abstract
This blog introduces AlphaPose, a top-down multi-person pose estimation framework designed to address critical challenges in traditional methods, such as detection box misalignment, heatmap quantization errors, and redundant pose suppression. The proposed multi-stage optimization strategy includes: first, the Symmetric Spatial Transformer Network (SSTN), which dynamically corrects detection box offsets through affine transformations to resolve keypoint centralization errors caused by inaccurate localization; second, the Symmetric Integral Keypoint Regression (SIKR), which introduces an Amplitude-Symmetric Gradient (ASG) to optimize the heatmap-to-coordinate conversion process, significantly reducing quantization errors in fine-grained regions like hands and feet; third, the Parametric Pose Non-Maximum Suppression (P-NMS), which dynamically suppresses redundant detections in crowded scenes by evaluating keypoint distance and pose orientation differences; and finally, the Pose-Guided Proposal Generator (PGPG), which enhances model robustness by simulating detector error distributions to generate diverse training data. While achieving outstanding performance in both accuracy and real-time efficiency, the framework remains highly dependent on detector performance and suffers from high computational complexity.
文章信息
Title:AlphaPose: Whole-Body Regional Multi-Person Pose Estimation and Tracking in Real-Time
Author:Hao-Shu Fang; Jiefeng Li; Hongyang Tang; Chao Xu; Haoyi Zhu; Yuliang Xiu
Source:https://arxiv.org/abs/2211.03375
引言
AlphaPose 是对多人全身人体姿态估计的研究,采用自顶向下框架,首先检测人体边界框,然后独立估计每个框内的姿态。
对于自顶向下的方法存在以下问题:
第一,姿态估计的结果以来人体检测器的效果,若人体检测器失效,就不能进行姿态估计。而且目前的研究为了准确度而采用强大的行人检测器,这使得两阶段处理的推理变慢。
第二,目前无论是自上而下还是自下而上的框架最常用的关键点表示都是heatmap,但由于计算资源的限制,heatmap尺寸通常是输入图像的四分之一,这就给精细关键点带来了量化误差。
第三,全身姿态估计缺乏训练数据,跨数据集训练面临域适应挑战。

方法

上图反映了AlphaPose的工作流程,首先利用现成的目标检测器如YOLOv3进行人体检测,得到一系列包含人体位置信息的边界框,边界框用四维坐标
(
x
,
y
,
w
,
h
)
(x,y,w,h)
(x,y,w,h) 来表示。然后,利用得到的边界框对原图进行裁剪得到人体图像,并对人体图像进行缩放,以确保输入到姿态估计网络的图像具有一致的尺寸。裁剪和缩放后的人体图像被送入人体姿态估计网络FastPose,得到人体全身的热图和RE-ID特征,并采用对称积分关键点回归方法从生成的热图中得到人体关键点的精确位置。为了消除重复的姿态,运用姿态非极大值抑制的方法来筛选并合并相近的姿态。为了进一步提升姿态识别精度,AlphaPose引入了一个姿势引导注意力模块(PGA),该模块能够根据预测的人体姿态优化re-ID特征提取过程,使得提取出的特征更加专注于人体本身而非背景干扰,从而的到更准确的Re-ID特征。最后,通过多阶段身份匹配算法,结合人体姿态、优化后的re-ID特征以及初始检测框的信息,系统能够为每个人分配一个唯一的跟踪标识,从而在复杂的多人场景中实现精准的个体跟踪。经过以上步骤,AlphaPose可以准确输出各个个体的关键点位置及其姿态信息,从而完成多人姿态估计和跟踪任务。
系统架构
两步框架的一个缺点是推理速度的限制。为了方便大规模数据的快速处理,AlphaPose设计了一个五阶段的pipeline与多处理实现,以加快推理。

将整个推理过程分为五个模块,遵循每个模块消耗相似的处理时间的原则。在推理过程中,每个模块都由独立的进程或线程托管。每个进程通过一个先进先出队列与后续进程通信,即它存储当前模块的计算结果,后续模块直接从队列中取出计算结果。通过这种设计,这些模块能够并行运行,从而显著提高速度并实现实时应用。
姿态估计器
AlphaPose的设计了FastPose姿态估计器,能够同时保证高准确度和高效率,其网络结构如下图所示:

FastPose采用 ResNet(如 ResNet-50/152)作为骨干网络,用于提取输入图像的特征。ResNet 的深层残差结构能够有效捕捉多尺度上下文信息,为关键点定位提供基础。为了提高特征图的分辨率,FastPose引入了三个Dense Upsampling Convolution (DUC)模块。DUC模块先通过二维卷积来扩大特征图的通道数,然后通过PixelShuffle 操作将低分辨率特征图重塑为高分辨率。最后,经过一个1×1 卷积层生成关键点热图(heatmaps)。这种设计通过DUC模块实现了高效的特征上采样,同时保留了丰富的空间信息,从而在姿态估计任务中实现了高精度和高效率的平衡。
下面是论文中开源的FastPose的搭建:
import torch.nn as nn
from .builder import SPPE
from .layers.DUC import DUC
from .layers.SE_Resnet import SEResnet
# 使用SPPE模块注册FastPose类,方便后续调用和管理
@SPPE.register_module
class FastPose(nn.Module):
def __init__(self, norm_layer=nn.BatchNorm2d, **cfg):
# 调用父类nn.Module的初始化方法
super(FastPose, self).__init__()
# 从配置参数中获取预设配置
self._preset_cfg = cfg['PRESET']
# 检查配置中是否包含卷积维度的参数
if 'CONV_DIM' in cfg.keys():
# 如果包含,则使用配置中的卷积维度
self.conv_dim = cfg['CONV_DIM']
else:
# 若不包含,默认卷积维度为128
self.conv_dim = 128
# 检查配置中是否包含可变形卷积网络(DCN)的相关参数
if 'DCN' in cfg.keys():
# 获取DCN相关的配置
stage_with_dcn = cfg['STAGE_WITH_DCN']
dcn = cfg['DCN']
# 初始化带有DCN的SE-ResNet骨干网络
self.preact = SEResnet(
f"resnet{cfg['NUM_LAYERS']}", dcn=dcn, stage_with_dcn=stage_with_dcn)
else:
# 若不使用DCN,初始化普通的SE-ResNet骨干网络
self.preact = SEResnet(f"resnet{cfg['NUM_LAYERS']}")
# 加载ImageNet预训练模型
import torchvision.models as tm # noqa: F401,F403
# 确保使用的ResNet层数在指定范围内
assert cfg['NUM_LAYERS'] in [18, 34, 50, 101, 152]
# 根据配置的层数加载对应的预训练ResNet模型
x = eval(f"tm.resnet{cfg['NUM_LAYERS']}(pretrained=True)")
# 获取当前骨干网络的状态字典
model_state = self.preact.state_dict()
# 筛选出预训练模型中与当前骨干网络匹配的参数
state = {k: v for k, v in x.state_dict().items()
if k in self.preact.state_dict() and v.size() == self.preact.state_dict()[k].size()}
# 将匹配的预训练参数更新到当前骨干网络的状态字典中
model_state.update(state)
# 加载更新后的状态字典到骨干网络中
self.preact.load_state_dict(model_state)
# 定义一个PixelShuffle层,用于上采样,将通道数缩小为原来的1/4,同时将特征图的尺寸扩大为原来的2倍
self.suffle1 = nn.PixelShuffle(2)
# 定义第一个DUC(Dynamic Upsampling Convolution)层,输入通道数为512,输出通道数为1024,上采样因子为2
self.duc1 = DUC(512, 1024, upscale_factor=2, norm_layer=norm_layer)
# 根据卷积维度的不同,定义第二个DUC层
if self.conv_dim == 256:
# 若卷积维度为256,第二个DUC层输入通道数为256,输出通道数为1024,上采样因子为2
self.duc2 = DUC(256, 1024, upscale_factor=2, norm_layer=norm_layer)
else:
# 若卷积维度不为256,第二个DUC层输入通道数为256,输出通道数为512,上采样因子为2
self.duc2 = DUC(256, 512, upscale_factor=2, norm_layer=norm_layer)
# 定义输出卷积层,将特征图的通道数转换为预设的关节点数
self.conv_out = nn.Conv2d(
self.conv_dim, self._preset_cfg['NUM_JOINTS'], kernel_size=3, stride=1, padding=1)
def forward(self, x):
# 输入数据通过骨干网络进行特征提取
out = self.preact(x)
# 通过PixelShuffle层进行上采样
out = self.suffle1(out)
# 通过第一个DUC层进行上采样和特征增强
out = self.duc1(out)
# 通过第二个DUC层进行上采样和特征增强
out = self.duc2(out)
# 通过输出卷积层得到最终的关节点预测结果
out = self.conv_out(out)
return out
def _initialize(self):
# 遍历输出卷积层的所有模块
for m in self.conv_out.modules():
# 检查当前模块是否为卷积层
if isinstance(m, nn.Conv2d):
# 使用正态分布初始化卷积层的权重,标准差为0.001
nn.init.normal_(m.weight, std=0.001)
# 将卷积层的偏置初始化为0
nn.init.constant_(m.bias, 0)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
对称积分关键点回归
热图是人体姿态估计领域中关节定位的主要表示,此前研究者认为基于soft-argmax的积分回归更适合全身关键点定位。但soft-argmax方法存在问题:反向传播时的梯度不对称,这破坏了网络的平移不变性。具体如下:
Soft-argmax操作,也称为积分回归,是可微的,它将基于heatmap的方法变成基于回归的方法,并允许端到端训练。积分回归操作定义为:
u
^
=
∑
x
⋅
p
x
\hat u=\sum x\cdot p_x
u^=∑x⋅px其中
x
x
x表示表示每个像素的坐标,
p
x
p_x
px表示像素
x
x
x上的热力值,热力值是归一化后的,满足所有位置的热力值之和为1。这个公式其实就是将热图的值看作概率,求坐标的期望。
在训练过程中,损失函数使用
L
1
L_1
L1损失函数:
L
reg
=
∥
μ
−
μ
^
∥
1
{\mathcal{L}}_{\text{reg }} = \parallel \mu - \widehat{\mu }{\parallel }_{1}
Lreg =∥μ−μ
∥1,每个像素的梯度为:
∂
L
reg
∂
p
x
=
∂
∥
u
−
u
^
∥
1
∂
u
^
∂
u
^
∂
p
x
=
−
sgn
(
u
−
u
^
)
x
=
x
sgn
(
u
^
−
u
)
\frac{\partial {L}_{\text{reg }}}{\partial {p}_{x}} = \frac{\partial \parallel u - \widehat{u}{\parallel }_{1}}{\partial \widehat{u}}\frac{\partial \widehat{u}}{\partial {p}_{x}}= - \operatorname{sgn}\left( {u - \widehat{u}}\right) x= x\operatorname{sgn}\left( {\widehat{u} - u}\right)
∂px∂Lreg =∂u
∂∥u−u
∥1∂px∂u
=−sgn(u−u
)x=xsgn(u
−u)梯度绝对值由像素的绝对位置(即x)来确定,而不是gt的相对位置。它表示在给定相同距离误差的情况下,当关键点位于不同位置时,梯度是不同的。

坐标越大,梯度的绝对值越大。这种不对称性会打破神经网络的平移不变性,导致网络的性能下降。
为了提高学习效率,AlphaPose提出一种反向传播中的幅值对称梯度(ASG)函数,它是真实梯度的近似值:
δ
A
S
G
=
A
grad
⋅
sgn
(
x
−
μ
^
)
⋅
sgn
(
μ
^
−
μ
)
{\delta }_{ASG} = {A}_{\text{grad }} \cdot \operatorname{sgn}\left( {x - \widehat{\mu }}\right) \cdot \operatorname{sgn}\left( {\widehat{\mu } - \mu }\right)
δASG=Agrad ⋅sgn(x−μ
)⋅sgn(μ
−μ)其中,
A
g
r
a
d
A_{grad}
Agrad表示梯度的幅值。这是一个常数,论文中设置为heatmap尺寸的1/8。这个函数是关于
u
^
\hat u
u^对称的。

在学习过程中,这种对称梯度分布可以更好的利用heatmap的优势,并以更直接的方式近似gt位置。例如,假设预测的位置 u ^ \hat u u^高于gt的 u u u。则网络倾向于抑制 u ^ \hat u u^右侧的heatmap值,因为它们具有正梯度;同时, u ^ \hat u u^左侧的heatmap值将会被激活。
两步热图归一化
在进行soft-argmax之前,预测的heatmap元素之和应归一化为1,即
∑
p
x
=
1
\sum p_x=1
∑px=1 ,因为热力值表示关键点出现在相应位置的概率。先前工作采用了soft-max操作,在单人姿态估计中效果良好,但在多人姿态估计中与SOTA技术仍有很大的性能差距。这是因为在多人情况下,不仅需要关节位置,还需要用于姿态NMS的关节置信度,并要计算mAP。在先前方法中,heatmap的最大值被视为关节置信度,这取决于尺寸依赖但并不准确。
上图是三个不同大小的关键点,关键点越大,其标准差越大,最大值越小;而关键点越小,热图的分布就会越集中,其最大值越大。所以soft-max得到的置信度与关键点的大小有关,并不可靠。
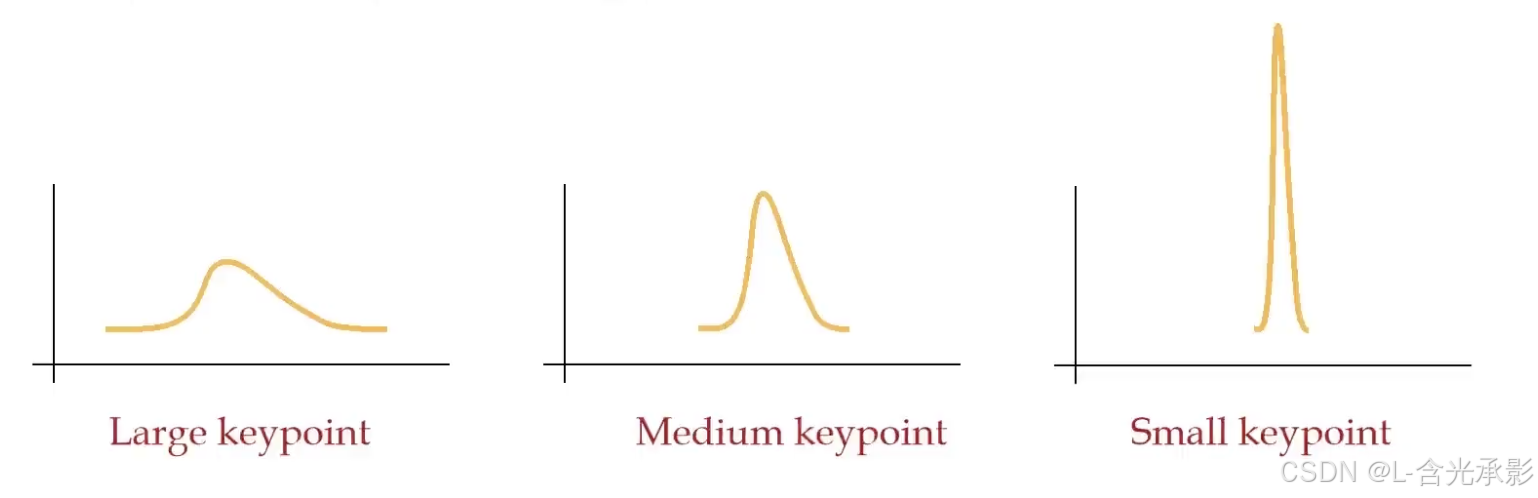
为了将置信度预测和积分回归解耦,AlphaPose提出了两步热图归一化方法。
第一步执行逐元素归一化,以生成置信heatmap C:
c
x
=
sigmoid
(
z
x
)
{c}_{x} = \operatorname{sigmoid}\left( {z}_{x}\right)
cx=sigmoid(zx)其中,
z
x
z_x
zx表示位置
x
x
x处未归一化的logits值,
c
x
c_x
cx表示位置
x
x
x处热图的置信值。所以关键点置信度可对此输出取最大值得到:
C
o
n
f
=
m
a
x
(
z
x
)
Conf=max(z_x)
Conf=max(zx)在归一化的第一步中使用逐元素操作sigmoid,并且不强制C的和为1,因此C的最大值不会受关节尺寸的影响。采用这种方式,预测的关节置信度仅与预测的位置有关。
第二步,执行全局归一化来生成概率热图P:
p
x
=
c
x
∑
C
p_x=\frac {c_x}{\sum C}
px=∑Ccx概率heatmap P的元素之和为1,这确保了预测的关节位置
u
^
\hat u
u^在heatmap边界内,并稳定了训练过程。
部位引导候选框生成
对于两阶段姿态估计,由行人检测器生成的人体proposal通常会产生与gt人体框不同的数据分布。同时,自然环境的全身图像与数据集中的part-only图像之间,其面部和手部的空间分布也不同。如果在训练过程中没有适当的数据增强,姿态估计器可能无法在测试阶段正常工作。
为了生成与行人检测器输出具有相似分布的训练样本,本文提出部位引导proposal生成器。对于具有紧密包围边界框的不同身体部位,proposal生成器生成一个新框,该框与行人检测器的输出分布一致。

既然已经有了每个部位的真实边界框,那么这个提案生成的任务可以简化为对不同部位侦测器给出的边界框和真实边界框之间相对偏移量的分布进行建模。假设侦测边界框和真实边界框之间的相对偏移量存在这样的一个分布:
P
(
δ
x
m
i
n
,
δ
x
m
a
x
,
δ
y
m
i
n
,
δ
y
m
a
x
∣
p
)
P(\delta x_{min},\delta x_{max},\delta y_{min},\delta y_{max}\left|p\right)
P(δxmin,δxmax,δymin,δymax∣p)其中,
p
p
p是关键点的类型,
δ
x
m
i
n
\delta x_{min}
δxmin和
δ
x
m
a
x
\delta x_{max}
δxmax是人体检测器生成的边界框最左/最右坐标与真实边界框之间归一化的偏移量:
δ
x
m
i
n
=
x
m
i
n
d
e
t
e
c
t
−
x
m
i
n
g
t
x
m
a
x
g
t
−
x
m
i
n
g
t
δ
x
m
a
x
=
x
m
a
x
d
e
t
e
c
t
−
x
m
a
x
g
t
x
m
a
x
g
t
−
x
m
i
n
g
t
δ
y
m
i
n
=
y
m
i
n
d
e
t
e
c
t
−
y
m
i
n
g
t
y
m
a
x
g
t
−
y
m
i
n
g
t
δ
y
m
a
x
=
y
m
a
x
d
e
t
e
c
t
−
y
m
a
x
g
t
y
m
a
x
g
t
−
y
m
i
n
g
t
δxmin=xdetectmin−xgtminxgtmax−xgtminδxmax=xdetectmax−xgtmaxxgtmax−xgtminδymin=ydetectmin−ygtminygtmax−ygtminδymax=ydetectmax−ygtmaxygtmax−ygtmin
δxmin=xmaxgt−xmingtxmindetect−xmingtδxmax=xmaxgt−xmingtxmaxdetect−xmaxgtδymin=ymaxgt−ymingtymindetect−ymingtδymax=ymaxgt−ymingtymaxdetect−ymaxgt使用了YOLOv3来生成人类侦测结果。由于边界框在水平和垂直上的变化是独立的,因此还可以进一步把上文提到的分布简化为水平方向和垂直方向的分布:
P
x
(
δ
x
m
i
n
,
δ
x
m
a
x
∣
p
)
\mathrm{P}_{x}\left(\delta x_{min},\delta x_{max}\left|p\right)\right.
Px(δxmin,δxmax∣p)
P
y
(
δ
y
m
i
n
,
δ
y
m
a
x
∣
p
)
.
\mathrm{P}_{y}\left(\delta y_{min},\delta y_{max}\left|p\right).\right.
Py(δymin,δymax∣p).在处理完Halpe-FullBody中的所有实例后,偏移形成频率分布,本文将数据拟合为高斯混合分布。对于不同身体部位,本文有不同的高斯混合参数。图3中可视化了分布及其对应部位。

在姿态估计器的训练阶段,对于属于部位p的训练样本,可以根据
P
x
(
δ
x
m
i
n
,
δ
x
m
a
x
∣
p
)
\mathrm{P}_{x}\left(\delta x_{min},\delta x_{max}\left|p\right)\right.
Px(δxmin,δxmax∣p)和
P
y
(
δ
y
m
i
n
,
δ
y
m
a
x
∣
p
)
.
\mathrm{P}_{y}\left(\delta y_{min},\delta y_{max}\left|p\right).\right.
Py(δymin,δymax∣p).通过密集采样,来生成对其gt边界框的额外偏移,以产生增强的训练proposal。
参数化姿态NMS
对于自顶向下方法,一个主要缺点是:如果行人检测器未能检测到人,姿态估计器就无法复原它。大多数基于自顶向下的方法都会遇到这个问题,因为它们将检测置信度设置为高值以避免冗余姿态。
但AlphaPose将检测置信度设置为低值,以确保较高的检测召回率。这种情况下,行人检测器必然会产生冗余检测,这会导致冗余姿态估计。因此,需要姿态非极大值抑制(NMS)来消除冗余。
先前方法要么效率不高,要么不够准确,AlphaPose提出一种参数化姿态NMS方法。
首先,选择最有把握的姿态作为参考,通过应用消除准则来消除一些与之接近的姿态。对剩余姿态集重复此过程,直到消除多余的姿态并仅给出唯一的姿态。
将具有m个关节的姿态
P
i
P _i
Pi表示为
P
i
=
{
(
k
i
1
,
c
i
1
)
,
⋯
,
(
k
i
m
,
c
i
m
)
}
P_{i}=\{(k_{i}^1,c_{i}^1),\cdots,\left(k_{i}^{m},c_{i}^{m}\right)\}
Pi={(ki1,ci1),⋯,(kim,cim)}
其中
k
i
j
k_i^j
kij和
c
i
j
c_i^j
cij分别表示第j个关节的位置和置信度分数。
消除标准:
先定义姿势相似度函数:
d
(
P
i
,
P
j
∣
Λ
)
d(P_i,P_j|\Lambda)
d(Pi,Pj∣Λ),
η
\eta
η是消除标准的阈值,
Λ
\Lambda
Λ是函数
d
(
⋅
)
d(\cdot)
d(⋅)中的参数集合,则消除标准可表示为:
f
(
P
i
,
P
j
∣
Λ
,
η
)
=
I
[
d
(
P
i
,
P
j
∣
Λ
,
λ
)
≤
η
]
f(P_i,P_j\left|\Lambda,\eta\right)=\mathbb{I}[d(P_i,P_j\left|\Lambda,\lambda\right)\leq\eta]
f(Pi,Pj∣Λ,η)=I[d(Pi,Pj∣Λ,λ)≤η]其中
I
\mathbb{I}
I是指示函数,当其输入为真时,输出为1,表示如果距离小于或等于阈值时,当前参与计算的姿势应该被消除。
姿势距离:
设姿势
P
i
P_i
Pi对应的边界框时
B
i
B_i
Bi,定义一个软匹配函数:
K
S
i
m
(
P
i
,
P
j
∣
σ
1
)
=
{
∑
n
tanh
c
i
n
σ
1
tanh
c
j
n
σ
1
,
if
k
j
n
在
B
(
k
i
n
)
中
0
,
else
.
\left.K_{Sim}\left(P_i,P_j|\sigma_1\right.\right)= {∑ntanhcniσ1tanhcnjσ1,if knj 在 B(kni) 中0,else.
KSim(Pi,Pj∣σ1)={∑ntanhσ1cintanhσ1cjn,0,if kjn 在 B(kin) 中else.其中,
B
(
k
i
n
)
B(k_i^n)
B(kin)是以
k
i
n
k_i^n
kin为中心的边界框,边界框对应的尺寸是
B
i
B_i
Bi的1/10。tanh操作过滤出置信度较低的姿态。当两个对应关节都具有高置信度分数时,输出更接近1的值。此距离会计算姿态之间匹配的关节数。
另外,还要考虑两个姿势的对应的关键点之间的空间距离:
H
S
i
m
(
P
i
,
P
j
∣
σ
2
)
=
∑
n
exp
[
−
(
k
i
n
−
k
j
n
)
2
σ
2
]
H_{Sim}(P_i,P_j|\sigma_2)=\sum_n\exp[-\frac{(k_i^n-k_j^n)^2}{\sigma_2}]
HSim(Pi,Pj∣σ2)=n∑exp[−σ2(kin−kjn)2]综合这两个距离,最终的距离函数可表示为:
d
(
P
i
,
P
j
∣
Λ
)
=
K
S
i
m
(
P
i
,
P
j
∣
σ
1
)
+
λ
H
S
i
m
(
P
i
,
P
j
∣
σ
2
)
d(P_i,P_j|\Lambda)=K_{Sim}(P_i,P_j|\sigma_1)+\lambda H_{Sim}(P_i,P_j|\sigma_2)
d(Pi,Pj∣Λ)=KSim(Pi,Pj∣σ1)+λHSim(Pi,Pj∣σ2)其中,参数集合
Λ
=
{
σ
1
,
σ
2
,
λ
}
\Lambda=\{\sigma_1,\sigma_2,\lambda\}
Λ={σ1,σ2,λ}.
姿态引导的注意力机制
re-ID特征可以用于从许多人体proposal中识别相同的个体。自顶向下框架中,从目标检测器产生的每个边界框中提取re-ID特征。但是,re-ID特征的质量会因边界框中的背景而降低,尤其是当存在其他人的身体时。为了解决这个问题,AlphaPose使用预测的人体姿态来构建一个人体集中的区域。因此,提出姿态引导注意(PGA),以迫使提取的特征集中在感兴趣的人体上,并忽略背景的影响。
姿态估计器生成k个heatmap,其中k表示每个人体的关键点数量。然后,PGA模块使用一个简单的conv层将这些heatmap转换为注意图(
m
A
m_A
mA)。
m
A
m_A
mA与re-ID特征图
m
i
d
m_{id}
mid的尺寸相同,所以可以获得加权的re-ID特征图
m
w
i
d
m_{wid}
mwid:
m
w
i
d
=
m
i
d
⊙
m
A
+
m
i
d
m_{wid}=m_{id}\odot m_A+m_{id}
mwid=mid⊙mA+mid其中
⊙
\odot
⊙表示Hadamard 乘积。
最后,身份嵌入
e
m
b
i
d
emb_{id}
embid是一个128维向量,由一个全连接层编码。
创新与不足
AlphaPose在多人姿态估计领域取得了显著突破,其核心创新点包括:提出对称积分回归,优化了反向传播的稳定性,降低了手部等精细关键点的定位误差;提出参数化姿态非极大值抑制,通过融合关键点距离和姿态方向差异定义动态相似度,精准消除冗余检测;提出姿态引导区域生成器,基于概率密度建模生成多样化检测框训练样本,增强了模型对定位偏差的鲁棒性;实时姿态跟踪,通结合跨帧姿态匹配与轨迹优化,解决视频中多人姿态的时序跳变问题。
AlphaPose虽然在多人姿态估计领域取得了显著进展,但仍存在以下不足:首先,其自顶向下的框架高度依赖目标检测模块,若检测器在遮挡或小目标场景中失效(如漏检),后续姿态估计将完全无法恢复 ;其次,计算复杂度较高 ;此外,参数化姿态非极大抑制(P-NMS)在复杂场景中表现受限,例如在极度拥挤的人群或高度相似姿态(如体操动作)中,可能出现误删正确检测或冗余抑制不彻底的问题 ;最后,实时性仍受挑战,密集人群场景下帧率可能降至15 FPS,且遮挡情况下的关键点定位精度和追踪稳定性显著下降,尤其在处理手部、面部等精细部位时量化误差仍较明显 。
总结
AlphaPose作为自顶向下的多人姿态估计框架,通过三步工作流程显著提升了密集场景下的姿态检测精度:首先利用目标检测器(如Faster R-CNN或YOLOv3)定位人体边界框;接着通过对称空间变换网络(SSTN)动态校正检测框偏移,将人体中心化后输入单人姿态估计器(如Stacked Hourglass)预测关键点;最后采用参数化姿态非极大抑制(P-NMS),基于关键点距离和姿态方向差异动态消除冗余检测。其核心创新包括对称积分关键点回归(SIKR)减少量化误差至传统方法的1/4,以及姿态引导区域生成器(PGPG)增强模型对检测误差的鲁棒性。然而,该框架仍存在高度依赖检测器性能、计算复杂度高(需中高端GPU支持)及密集相似姿态抑制不足等局限。未来研究可聚焦轻量化部署(如移动端优化)、多模态融合(结合自底向上方法提升遮挡处理能力)以及跨领域扩展(如医疗康复、自动驾驶中的精细姿态分析)。

















 1033
1033




 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言