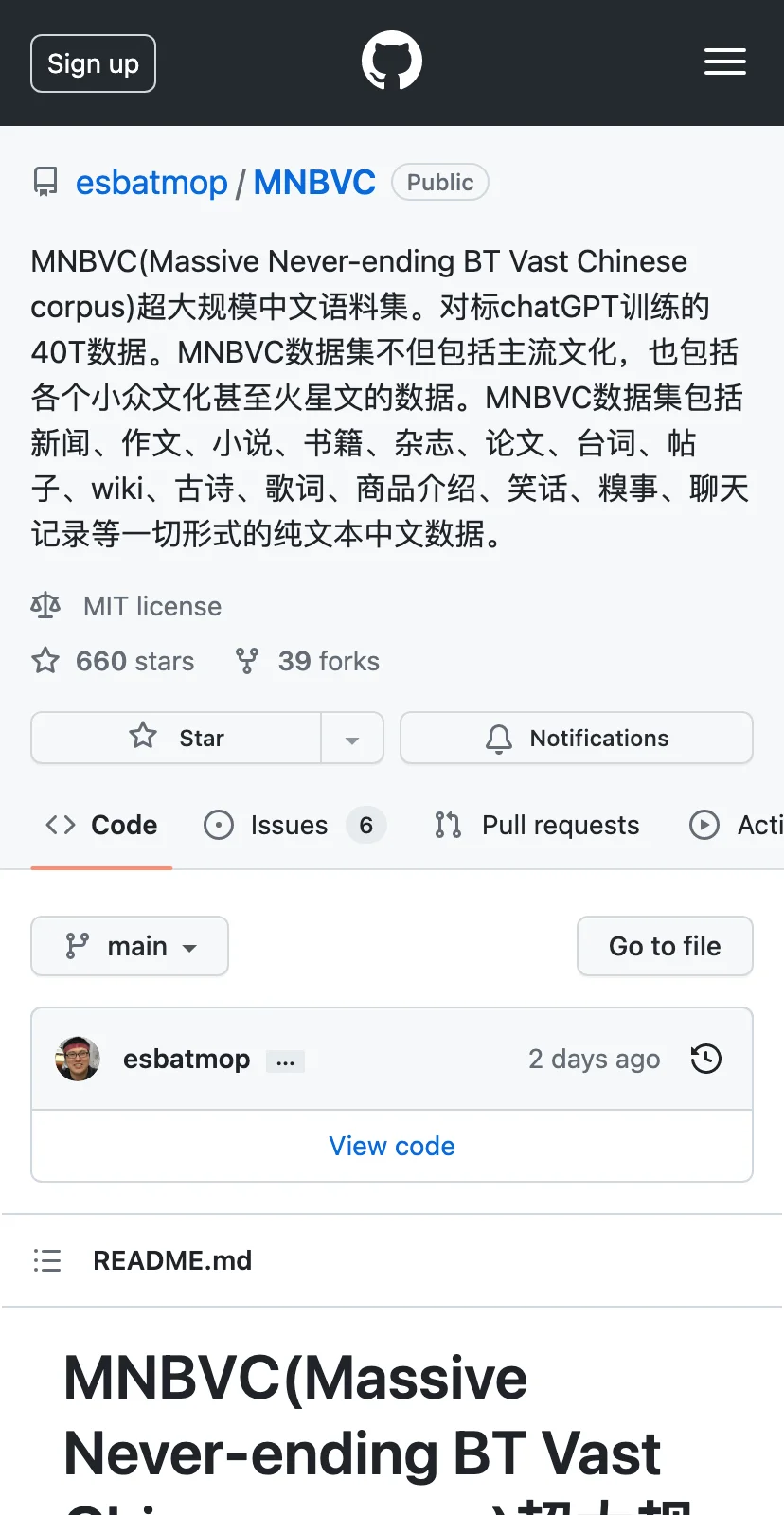

这个网站是 MNBVC,即 Massive Never-ending BT Vast Chinese corpus,一个超大规模的中文语料集。该语料集对标 chatGPT 训练的 40T 数据。MNBVC 数据集不仅包括主流文化,还包括各个小众文化甚至火星文的数据。它包括新闻、作文、小说、书籍、杂志、论文、台词、帖子、wiki、古诗、歌词、商品介绍、笑话、糗事、聊天记录等一切形式的纯文本中文数据。如果你在进行自然语言处理的研究、开发和应用方面需要中文语料,MNBVC 是你不错的选择,尤其是在需要涵盖各种小众文化或极端文本的时候。MNBVC 可以帮助你训练更加准确和全面的中文自然语言处理模型,让你的应用效果更好,覆盖面更广。在 MNBVC 的 GitHub 页面上,你可以下载语料集、查看文档和示例,并了解其他人对此语料集的使用和评价。
电脑端截图
移动端截图